Another MCMC method beside Metropolis-Hastings and Gibbs Sampling, Slice Sampling generates random samples based on their previous states. Those samples then could be used to compute integrals (mean, median, etc) or just to plot the histogram, like I’ll do here.
Compared to M-H and Gibbs Sampling, Slice Sampling doesn’t need any helper distribution. Whereas M-H needs us to pick a transition distribution Q(x -> x'), and Gibbs Sampling needs us to find full conditionals of the joint distribution analytically, Slice Sampling will only need us to provide the target distribution.
For a special case of Slice Sampling where target distribution P(x) is unimodal, if we could get our hand to the inverse function of the PDF, implementing Slice Sampling will be a breeze. This post will only cover this special case as it’s the simplest.
Let’s say we have a Standard Normal from which we want to sample with Slice Sampling. Because Gaussian is unimodal, and the inverse PDF could be easily found analytically, it fits this special case. I’m not going to put the step by step derivation of the inverse PDF here as this blog don’t have math engine to render formula.
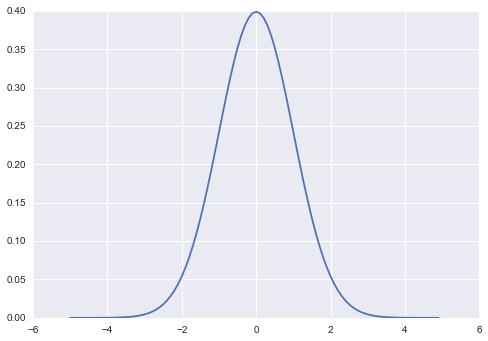
The PDF and inverse PDF of Standard Normal are as follow in Python code:
def p(x): return np.exp(-(x**2) / 2) / (np.sqrt(2*np.pi))
def p_inv(y): return np.sqrt(-2 * np.log(y _ np.sqrt(2*np.pi)))Here’s the inverse PDF of that Gaussian:
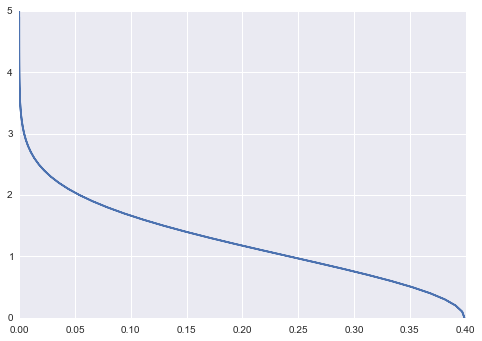
Why do we need the inverse PDF? Recall that if we have y = f(x), then if we have y, we could find the x using the inverse function: x = f_inv(y). To give you some visualization, consider a Gaussian. The PDF will give you probability P(x) when you feed it with some x. Now what happen if we want to know, which x would yield this probability P(x)? That’s where the inverse function comes in. Similarly, think about the relation of CDF and Quantile Function of probability distribution. Quantile Function is an inverse of CDF. Given an x, CDF will give you cumulative probability up to x. Given a cumulative probability c, Quantile Function will give you the x such that the cumulative probability at point x is c.
Here’s the algorithm for Standard Normal case (mu = 0, sigma = 1):
- Set a starting point
x - Sample the height
u ~ Unif(0, p(x)) - Sample the next
x ~ Unif(-z, z), wherezis the inverse PDF evaluated atu - Go to step 2
As you can see right away, this is MCMC indeed, as to get the next sample of x depends on auxiliary variable u, which in turn depends on the current sample of x.
Intuitively, let’s say our starting point is x = 0. Then the Slice Sampler will sample a height at that point uniformly from 0 up to the height of the true distribution, or a function that’s proportional to the true distribution. That means the sampler will sample u ~ Unif(0, 0.4). Now let’s say u is 0.25, we then use our inverse PDF to find z, which is x at the right boundary of the curve, which is 1. The inverse function of Gaussian is the right half of that Gaussian. If we’re sampling uniformly from [-z, z]: x ~ Unif(-z, z), because Gaussian is symmetric, then it means that we’re sampling the line segment that slicing the area under the curve at height u. Using the new x, we proceed to find the new u, and so on, rinse and repeat until we get the number of samples we want.
The example above is for Standard Normal, the special case of Gaussian. If we want to use generalize the Slice Sampler, then we need to do some modification. First, we need to derive the generalized inverse Gaussian PDF, which means we need to take parameter mu and sigma into account when inversing the PDF. Second, we need to take into account the mu when finding the line segment. mu in Gaussian is used to shift the center of the distribution. Because in Standard Normal the mu is 0, we could leave that out. But for general Gaussian, the range of the line segment under the curve at height u would be [mu-z, mu+z].
Let’s see that in the code. Here, in the code, I picked an arbitrary parameter for the Gaussian, mu=65 and sigma=32.
import numpy as npimport scipy.stats as stimport seaborn as snsimport matplotlib.pyplot as plt
sns.set()mu = 65sigma = 32
def p(x): return st.norm.pdf(x, loc=mu, scale=sigma)
def p*inv(y): x = np.sqrt(-2*sigma**2 * np.log(y * sigma _ np.sqrt(2*np.pi))) return mu-x, mu+x
def slice_sampling(iter=1000): samples = np.zeros(iter) x = 0
for i in range(iter): u = np.random.uniform(0, p(x)) x_lo, x_hi = p_inv(u) x = np.random.uniform(x_lo, x_hi) samples[i] = x
return samples
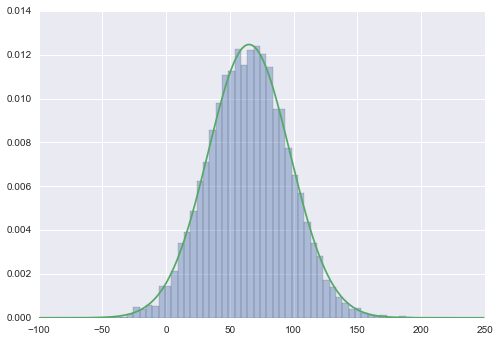
if __name__ == '__main__': samples = slice_sampling(iter=10000) sns.distplot(samples, kde=False, norm_hist=True) x = np.arange(-100, 250) plt.plot(x, p(x)) plt.show()Here’s the sampling result. The green curve is the real PDF of Normal(65, 32).
Slice Sampling, being MCMC method, obviously shares some characteristic of the other MCMC methods like Metropolis-Hastings or Gibbs Sampling. Because it’s Markovian, then there is a correlation between samples, which makes the samples not i.i.d. To remedy that, we could use technique called thinning, to only collect sample after some iteration to reduce the correlation. Another thing is that we should consider some burn-in period before collecting sample, to make sure we get only samples we care.
The advantage of Slice Sampling compared to M-H and Gibbs Sampling of course is that we don’t need to derive or pick anything other than a function that is proportional to the true distribution. However, the implementation of generalized Slice Sampling is rather complicated because we have to consider a lot more cases like when the distribution is multimodal, etc. The hardest part would be to find the line segment under the curve at height u. The special case on multimodal distribution makes finding the line segment really easy.
In this post, we only evaluated Slice Sampling for one dimensional distribution. To sample from multidimensional distribution, we could use Slice Sampling like Gibbs Sampling: run the sampler in turn for each dimension.