/ 7 min read
Implementing Minibatch Gradient Descent for Neural Networks
It’s a public knowledge that Python is the de facto language of Machine Learning. It’s not without reason: Python has a very healthy and active libraries that are very useful for numerical computing. Libraries like Numpy, SciPy, Pandas, Matplotlib, etc are very important building blocks for implementing Machine Learning algorithms.
So, let’s back to basic and learn how to create a simple 3-layers Neural Networks, and implement Minibatch Gradient Descent using Numpy.
Defining the Networks
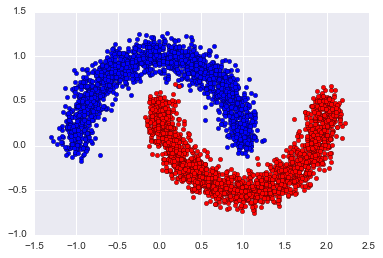
First, the dataset. We’re going to create toy dataset by using Scikit-Learn make_moons function:
from sklearn.datasets import make_moonsfrom sklearn.cross_validation import train_test_split
X, y = make_moons(n_samples=5000, random_state=42, noise=0.1)X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)To get clearer picture about the dataset, here’s the visualization:
Next, we define our NN model. It will be a three layers networks (single hidden layer):
import numpy as np
n_feature = 2n_class = 2n_iter = 10
def make_network(n_hidden=100): # Initialize weights with Standard Normal random variables model = dict( W1=np.random.randn(n_feature, n_hidden), W2=np.random.randn(n_hidden, n_class) )
return modelWe will also define two operations: forward propagation and the backpropagation. Let’s digest them one by one. We’re going to define the forward propagation first.
def softmax(x): return np.exp(x) / np.exp(x).sum()
def forward(x, model): # Input to hidden h = x @ model['W1'] # ReLU non-linearity h[h < 0] = 0
# Hidden to output prob = softmax(h @ model['W2'])
return h, probThe basic scheme is to do series of dot product from input to hidden layer to output layer. In the hidden layer, we also apply some kind of non-linearity so that our NN could predict non-linear decision boundary. The hottest non-linearity function right now is ReLU, and we’re going to follow that trend.
Now, ReLU is defined by f(x) = max(0, x). But, rather than doing np.max(0, x), there’s a neat implementation trick: x[x < 0] = 0. It’s subjectively more readable.
Once we reach the output layer, we need to make the output to be a probability distribution, Bernoulli to be exact, so we squash the output with Softmax function to get our label distribution.
def backward(model, xs, hs, errs): """xs, hs, errs contain all informations (input, hidden state, error) of all data in the minibatch""" # errs is the gradients of output layer for the minibatch dW2 = hs.T @ errs
# Get gradient of hidden layer dh = errs @ model['W2'].T dh[hs <= 0] = 0
dW1 = xs.T @ dh
return dict(W1=dW1, W2=dW2)For the backprop, we start from the top (output layer) down to the input layer. We start by propagating the error to get the gradient of weight between hidden layer and output layer, then we compute the gradient of hidden layer using the error gradient. Using hidden layer gradient, we then compute the gradient of weight between input and hidden layer.
Gradient Descent
We could use the model already, but it’s meaningless as it will yield random result (because of random initialization). So, what we need to do is to train the networks with our dataset.
The most popular optimization algorithm in Machine Learning is Gradient Descent. It’s a first order method, meaning that we only need to compute the gradient of the objective function to use it. Compared to the second order method like Netwon’s Method or BFGS, where we have to derive the partial second order derivative matrix (Hessian), Gradient Descent is simpler, albeit we have more to fiddle about.
Now, there are three variants of Gradient Descent: Batch, Stochastic, and Minibatch:
- Batch will use full training data at each iteration, with could be very expensive if our dataset is large and our networks have a lot of parameters.
- Stochastic uses only single data point to propagate the error, which would make the convergence slow, as the variance is big (because Law of Large Numbers doesn’t apply).
- Minibatch is combining the best of both worlds. We don’t use full dataset but we also don’t use single data point either. For example, we’re using 50, 100, or 200 random subset of our dataset each time we train the networks. This way, we lower the computation cost, and yet we’re still get lower variance than by using the Stochastic version.
Implementing the Minibatch Gradient Descent
Let’s apply our algorithm of choice Minibatch Gradient Descent:
def sgd(model, X_train, y_train, minibatch_size): for iter in range(n_iter): print('Iteration {}'.format(iter))
# Randomize data point X_train, y_train = shuffle(X_train, y_train)
for i in range(0, X_train.shape[0], minibatch_size): # Get pair of (X, y) of the current minibatch/chunk X_train_mini = X_train[i:i + minibatch_size] y_train_mini = y_train[i:i + minibatch_size]
model = sgd_step(model, X_train_mini, y_train_mini)
return modelThis is the skeleton of our training algorithm. Notice how we first shuffle the training data first then get chunks from it. That way we will get the random subset with size of minibatch_size of our full training data. Each of those random subset will be fed to the networks, and then the gradients of that minibatch will be propagate back to update the parameters/weights of the networks.
The sgd_step function is like this:
def sgd_step(model, X_train, y_train): grad = get_minibatch_grad(model, X_train, y_train) model = model.copy()
# Update every parameters in our networks (W1 and W2) using their gradients for layer in grad: # Learning rate: 1e-4 model[layer] += 1e-4 * grad[layer]
return modelFirst, we get the gradients of each layer of the networks for the current minibatch. Then we use that gradients to update the weights of each layers of the networks. The update operation is very easy. We just add the gradient of particular weight matrix to our existing weight matrix.
To make the learning better, we scale the gradients with a learning rate hyperparameter. If we think visually, the gradient of a function is the direction of our step, whereas the learning rate is how far we take the step.
Lastly, we look at our get_minibatch_grad function:
def get_minibatch_grad(model, X_train, y_train): xs, hs, errs = [], [], []
for x, cls_idx in zip(X_train, y_train): h, y_pred = forward(x, model)
# Create probability distribution of true label y_true = np.zeros(n_class) y_true[int(cls_idx)] = 1.
# Compute the gradient of output layer err = y_true - y_pred
# Accumulate the informations of minibatch # x: input # h: hidden state # err: gradient of output layer xs.append(x) hs.append(h) errs.append(err)
# Backprop using the informations we get from the current minibatch return backward(model, np.array(xs), np.array(hs), np.array(errs))What we do here is to iterate every data point in our minibatch, then feed it to the network and compare the output with the true label from the training data. The error is neatly defined by the difference of the probability of true label with the probability of our prediction. This is so, because we’re implicitly using the Softmax output with Cross Entropy cost function. See here for full derivation: http://math.stackexchange.com/questions/945871/derivative-of-softmax-loss-function.
Because this is a Minibatch Gradient Descent algorithm, we then accumulate all the informations of the current minibatch. We use all those informations of the current minibatch to do the backprop, which will yield gradients of the networks’ parameters (W1 and W2).
Testing
Let’s test our model and algorithm. We’re going to repeat the train-test procedure for 100 times then report the average of the accuracy.
minibatch_size = 50n_experiment = 100
# Create placeholder to accumulate prediction accuracyaccs = np.zeros(n_experiment)
for k in range(n_experiment): # Reset model model = make_network()
# Train the model model = sgd(model, X_train, y_train, minibatch_size)
y_pred = np.zeros_like(y_test)
for i, x in enumerate(X_test): # Predict the distribution of label _, prob = forward(x, model) # Get label by picking the most probable one y = np.argmax(prob) y_pred[i] = y
# Compare the predictions with the true labels and take the percentage accs[k] = (y_pred == y_test).sum() / y_test.size
print('Mean accuracy: {}, std: {}'.format(accs.mean(), accs.std()))With 10 iterations and minibatch size of 50, here’s what we get:
Mean accuracy: 0.8765040000000001, std: 0.0048433442991387705So, we get about 87% accuracy on average. Not bad at all!
Conclusion and Future Work
Here, we showed how to define a simple Neural Networks model from scratch using Numpy. We also defined the forward and backpropagation operations of the networks. We then wrote an algorithm to train the network: Minibatch Gradient Descent. Finally we tested the trained networks using test dataset.
This model obviously a very simple Neural Networks model. If you noticed, it doesn’t even have bias! Nevertheless it served our purpose: implementing the Minibatch Gradient Descent algorithm.
Think of this post and codes as the foundation of the next posts about the more sophisticated and better optimization algorithms.