Previously, we looked at the Fisher Information Matrix. We saw that it is equal to the negative expected Hessian of log likelihood. Thus, the immediate application of Fisher Information Matrix is as drop-in replacement of Hessian in second order optimization algorithm. In this article, we will look deeper at the intuition on what excatly is the Fisher Information Matrix represents and what is the interpretation of it.
Distribution Space
As per previous article, we have a probabilistic model represented by its likelihood
Usual way to solve this optimization is to use gradient descent. In this case, we are taking step which direction is given by
The above expression is saying that the steepest descent direction in parameter space is to pick a vector
Meanwhile, if our objective is to minimize the loss function (maximizing the likelihood), then it is natural that we taking step in the space of all possible likelihood, realizable by parameter
Which metric/distance then do we need to use in this space? A popular choice would be KL-divergence. KL-divergence measure the “closeness” of two distributions. Although as KL-divergence is non-symmetric and thus not a true metric, we can use it anyway. This is because as
We can see the problem when using only Euclidean metric in parameter space from the illustrations below. Consider a Gaussian parameterized by only its mean and keep the variance fixed to 2 and 0.5 for the first and second image respectively:
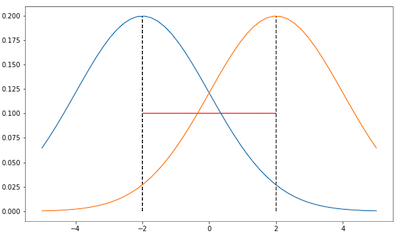
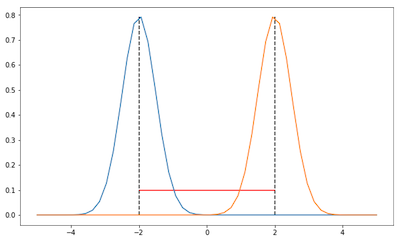
In both images, the distance of those Gaussians are the same, i.e. 4, according to Euclidean metric (red line). However, clearly in distribution space, i.e. when we are taking into account the shape of the Gaussians, the distance is different in the first and second image. In the first image, the KL-divergence should be lower as there is more overlap between those Gaussians. Therefore, if we only work in parameter space, we cannot take into account this information about the distribution realized by the parameter.
Fisher Information and KL-divergence
One question still needs to be answered is what exactly is the connection between Fisher Information Matrix and KL-divergence? It turns out, Fisher Information Matrix defines the local curvature in distribution space for which KL-divergence is the metric.
Claim:
Fisher Information Matrix
Proof. KL-divergence can be decomposed into entropy and cross-entropy term, i.e.:
The first derivative wrt.
The second derivative is:
Thus, the Hessian wrt.
The last line follows from the previous post about Fisher Information Matrix, in which we showed that the negative expected Hessian of log likelihood is the Fisher Information Matrix.
Steepest Descent in Distribution Space
Now we are ready to use the Fisher Information Matrix to enhance the gradient descent. But first, we need to derive the Taylor series expansion for KL-divergence around
Claim:
Let
Proof. We will use
Notice that the first term is zero as it is the same distribution. Furthermore, from the previous post, we saw that the expected value of the gradient of log likelihood, which is exactly the gradient of KL-divergence as shown in the previous proof, is also zero. Thus the only thing left is:
Now, we would like to know what is update vector
where
If we write the above minimization in Lagrangian form, with constraint KL-divergence approximated by its second order Taylor series expansion and approximate
To solve this minimization, we set its derivative wrt.
Up to constant factor of
Definition: Natural gradient is defined as
As corollary, we have the following algorithm:
Algorithm: Natural Gradient Descent
- Repeat:
- Do forward pass on our model and compute loss
- Compute the gradient
- Compute the Fisher Information Matrix
- Compute the natural gradient
- Update the parameter:
- Do forward pass on our model and compute loss
- Until convergence.
Discussion
In the above very simple model with low amount of data, we saw that we can implement natural gradient descent easily. But how easy is it to do this in the real world? As we know, the number of parameters in deep learning models is very large, within millions of parameters. The Fisher Information Matrix for these kind of models is then infeasible to compute, store, or invert. This is the same problem as why second order optimization methods are not popular in deep learning.
One way to get around this problem is to approximate the Fisher/Hessian instead. Method like ADAM [4] computes the running average of first and second moment of the gradient. First moment can be seen as momentum which is not our interest in this article. The second moment is approximating the Fisher Information Matrix, but constrainting it to be diagonal matrix. Thus in ADAM, we only need
References
- Martens, James. “New insights and perspectives on the natural gradient method.” arXiv preprint arXiv:1412.1193 (2014).
- Ly, Alexander, et al. “A tutorial on Fisher information.” Journal of Mathematical Psychology 80 (2017): 40-55.
- Pascanu, Razvan, and Yoshua Bengio. “Revisiting natural gradient for deep networks.” arXiv preprint arXiv:1301.3584 (2013).
- Kingma, Diederik P., and Jimmy Ba. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014).