Kullback-Leibler Divergence, or KL Divergence is a measure on how “off” two probability distributions
For example, if we have two gaussians,
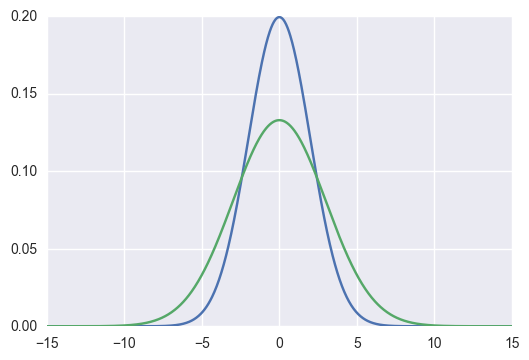
The KL Divergence could be computed as follows:
that is, for all random variable
KL Divergence in optimization
In optimization setting, we assume that
Just like any other distance functions (e.g. euclidean distance), we can use KL Divergence as a loss function in an optimization setting, especially in a probabilistic setting. For example, in Variational Bayes, we are trying to fit an approximate to the true posterior, and the process to make sure that
However, we have to note this important property about KL Divergence: it is not symmetric. Formally,
Forward KL
In forward KL, the difference between
Consider
Reversely, if
Let’s see some visual examples.
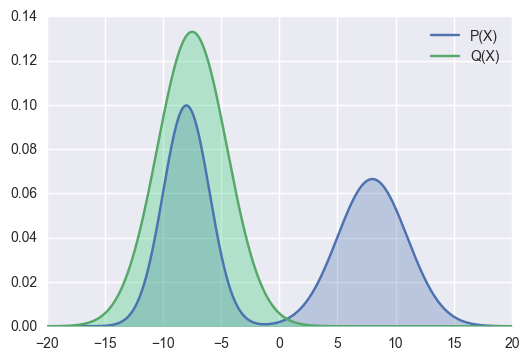
In the example above, the right hand side mode is not covered by
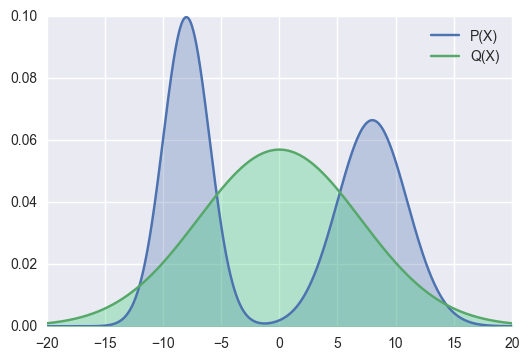
In the above example,
Although there are still some area that are wrongly covered by
Those are the reason why, Forward KL is known as zero avoiding, as it is avoiding
Reverse KL
In Reverse KL, as we switch the two distributions’ position in the equation, now
First, what happen if
Second, what happen if
Therefore, the failure case example above for Forward KL, is the desireable outcome for Reverse KL. That is, for Reverse KL, it is better to fit just some portion of
Consequently, Reverse KL will try avoid spreading the approximate. Now, there would be some portion of
As those properties suggest, this form of KL Divergence is know as zero forcing, as it forces
Conclusion
So, what’s the best KL?
As always, the answer is “it depends”. As we have seen above, both has its own characteristic. So, depending on what we want to do, we choose which KL Divergence mode that’s suitable for our problem.
In Bayesian Inference, esp. in Variational Bayes, Reverse KL is widely used. As we could see at the derivation of Variational Autoencoder, VAE also uses Reverse KL (as the idea is rooted in Variational Bayes!).
References
- Blei, David M. “Variational Inference.” Lecture from Princeton, https://www. cs. princeton. edu/courses/archive/fall11/cos597C/lectures/variational-inference-i. pdf (2011).
- Fox, Charles W., and Stephen J. Roberts. “A tutorial on variational Bayesian inference.” Artificial intelligence review 38.2 (2012): 85-95.