/ 5 min read
Conditional Generative Adversarial Nets in TensorFlow
We have seen the Generative Adversarial Nets (GAN) model in the previous post. We have also seen the arch nemesis of GAN, the VAE and its conditional variation: Conditional VAE (CVAE). Hence, it is only proper for us to study conditional variation of GAN, called Conditional GAN or CGAN for short.
CGAN: Formulation and Architecture
Recall, in GAN, we have two neural nets: the generator
We can see it with a probabilistic point of view.
Likewise for the discriminator, now it tries to find discriminating label for
Hence, we could see that both
Now, the objective function is given by:
If we compare the above loss to GAN loss, the difference only lies in the additional parameter
The architecture of CGAN is now as follows (taken from [1]):
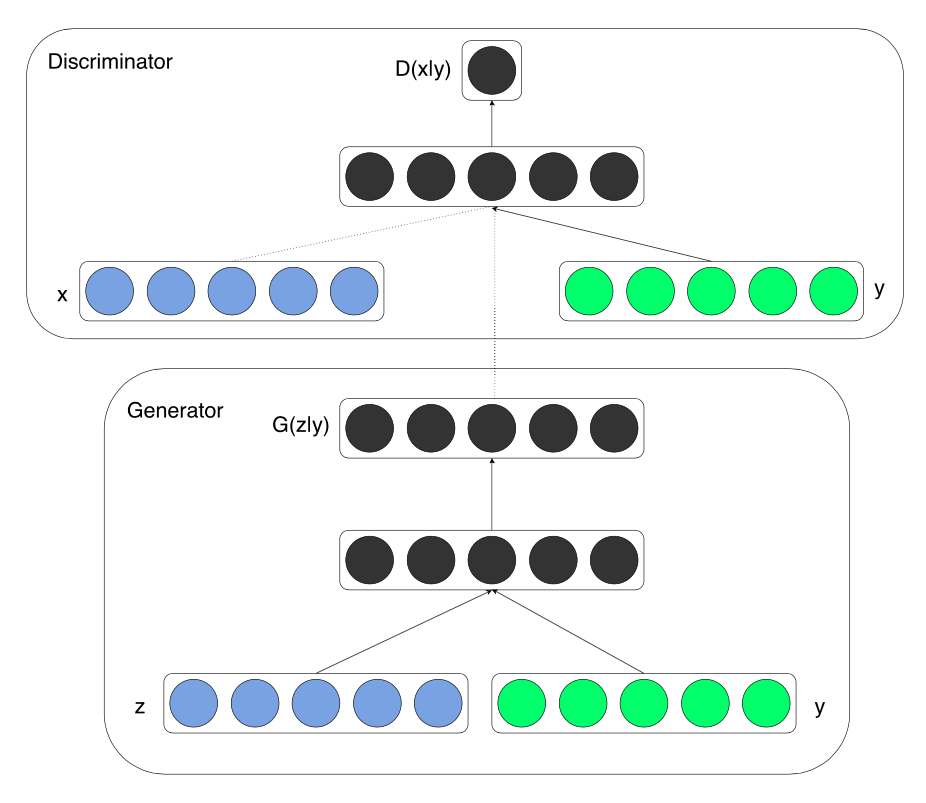
In contrast with the architecture of GAN, we now has an additional input layer in both discriminator net and generator net.
CGAN: Implementation in TensorFlow
Implementing CGAN is so simple that we just need to add a handful of lines to the original GAN implementation. So, here we will only look at those modifications.
The first additional code for CGAN is here:
y = tf.placeholder(tf.float32, shape=[None, y_dim])We are adding new input to hold our variable we are conditioning our CGAN to.
Next, we add it to both our generator net and discriminator net:
def generator(z, y): # Concatenate z and y inputs = tf.concat(concat_dim=1, values=[z, y])
G_h1 = tf.nn.relu(tf.matmul(inputs, G_W1) + G_b1) G_log_prob = tf.matmul(G_h1, G_W2) + G_b2 G_prob = tf.nn.sigmoid(G_log_prob)
return G_prob
def discriminator(x, y): # Concatenate x and y inputs = tf.concat(concat_dim=1, values=[x, y])
D_h1 = tf.nn.relu(tf.matmul(inputs, D_W1) + D_b1) D_logit = tf.matmul(D_h1, D_W2) + D_b2 D_prob = tf.nn.sigmoid(D_logit)
return D_prob, D_logitThe problem we have here is how to incorporate the new variable
Of course, as our inputs for
# Modify input to hidden weights for discriminatorD_W1 = tf.Variable(shape=[X_dim + y_dim, h_dim]))
# Modify input to hidden weights for generatorG_W1 = tf.Variable(shape=[Z_dim + y_dim, h_dim]))That is, we just adjust the dimensionality of our weights.
Next, we just use our new networks:
# Add additional parameter y into all networksG_sample = generator(Z, y)D_real, D_logit_real = discriminator(X, y)D_fake, D_logit_fake = discriminator(G_sample, y)And finally, when training, we also feed the value of
X_mb, y_mb = mnist.train.next_batch(mb_size)
Z_sample = sample_Z(mb_size, Z_dim)_, D_loss_curr = sess.run([D_solver, D_loss], feed_dict={X: X_mb, Z: Z_sample, y:y_mb})_, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={Z: Z_sample, y:y_mb})As an example above, we are training our GAN with MNIST data, and the conditional variable
CGAN: Results
At test time, we want to generate new data samples with certain label. For example, we set the label to be 5, i.e. we want to generate digit “5”:
n_sample = 16Z_sample = sample_Z(n_sample, Z_dim)
# Create conditional one-hot vector, with index 5 = 1y_sample = np.zeros(shape=[n_sample, y_dim])y_sample[:, 5] = 1
samples = sess.run(G_sample, feed_dict={Z: Z_sample, y:y_sample})Above, we just sample
Here is the results:

Looks pretty much like digit 5, right?
If we set our one-hot vectors to have value of 1 in the 7th index:

Those results confirmed that have successfully trained our CGAN.
Conclusion
In this post, we looked at the analogue of CVAE for GAN: the Conditional GAN (CGAN). We show that to make GAN into CGAN, we just need a little modifications to our GAN implementation.
The conditional variables for CGAN, just like CVAE, could be anything. Hence it makes CGAN an interesting model to work with for data modeling.
The full code is available at my GitHub repo: https://github.com/wiseodd/generative-models.
References
- Mirza, Mehdi, and Simon Osindero. “Conditional generative adversarial nets.” arXiv preprint arXiv:1411.1784 (2014).