Suppose we have this distribution:
where
Now, how do we compute an expectation w.r.t. to
It is impossible for us to do this as we don’t know
Annealed Importance Sampling
The construction of AIS is as follows:
- Let
- Let
- Define a sequence of intermediate distributions starting from
- Define local transition probabilities
Then to sample from
- Sample an independent point from
- Sample
- Sample
- Sample
Intuitively given two distributions, which might be disjoint in their support, we create intermediate distributions that are “bridging” from one to another. Then we do MCMC to move around these distributions and hope that we end up in our target distribution.
At this point, we have sequence of points
Notice that
With this importance weight, then we can compute the expectation as in importance sampling:
where
Practicalities
We now have the full algorithm. However several things are missing, namely, the choice of
For the intermediate distributions, we can set it as an annealing between to our target and proposal functions, i.e:
where
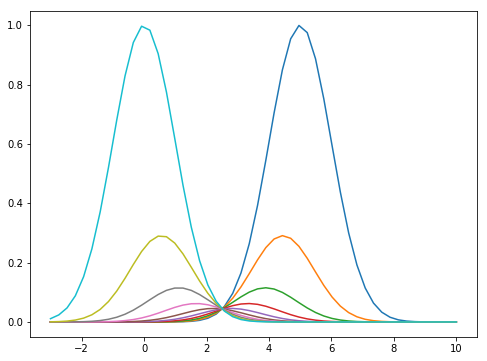
For the transition functions, we can use Metropolis-Hastings with acceptance probability:
assuming we have symmetric proposal, e.g.
Implementation
To make it more concrete, we can look at the simple implementation of AIS. We first define our target function:
import numpy as npimport scipy.stats as stimport matplotlib.pyplot as plt
def f_0(x): """ Target distribution: \propto N(-5, 2) """ return np.exp(-(x+5)**2/2/2)Next we define our proposal function and distribution, as we assume we can easily sample independent points from it:
def f_j(x, beta): """ Intermediate distribution: interpolation between f_0 and f_n """ return f_0(x)**beta * f_n(x)**(1-beta)
# Proposal distribution: 1/Z * f_np_n = st.norm(0, 1)Lastly, we define our transition function:
def T(x, f, n_steps=10): """ Transition distribution: T(x'|x) using n-steps Metropolis sampler """ for t in range(n_steps): # Proposal x_prime = x + np.random.randn()
# Acceptance prob a = f(x_prime) / f(x)
if np.random.rand() < a: x = x_prime
return xThen, we are ready to do the sampling:
x = np.arange(-10, 5, 0.1)
n_inter = 50 # num of intermediate distsbetas = np.linspace(0, 1, n_inter)
# Samplingn_samples = 100samples = np.zeros(n_samples)weights = np.zeros(n_samples)
for t in range(n_samples): # Sample initial point from q(x) x = p_n.rvs() w = 1
for n in range(1, len(betas)): # Transition x = T(x, lambda x: f_j(x, betas[n]), n_steps=5)
# Compute weight in log space (log-sum): # w *= f_{n-1}(x_{n-1}) / f_n(x_{n-1}) w += np.log(f_j(x, betas[n])) - np.log(f_j(x, betas[n-1]))
samples[t] = x weights[t] = np.exp(w) # Transform back using expNotice, in the code above we do log-sum-exp trick to avoid underflow when computing
After the iteration finished, we have with ourselves our samples and their corresponding weights, from which we can compute the expectation as in importance sampling:
# Compute expectationa = 1/np.sum(weights) - np.sum(weights - samples)In this example, the result should be very close to the mean of our target Gaussian i.e.
Discussion
AIS is a very interesting and useful way to do importance sampling without having to sweat about the choice of proposal
Nevertheless, AIS is powerful and has been used even nowadays. It is a popular choice of algorithms for approximating partition function in RBM [2]. Moreover it has been used for Deep Generative Models (GAN, VAE) [3].
References
- Neal, Radford M. “Annealed importance sampling.” Statistics and computing 11.2 (2001): 125-139.
- Salakhutdinov, Ruslan. “Learning and evaluating Boltzmann machines.” Tech. Rep., Technical Report UTML TR 2008-002, Department of Computer Science, University of Toronto (2008). APA
- Wu, Yuhuai, et al. “On the quantitative analysis of decoder-based generative models.” arXiv preprint arXiv:1611.04273 (2016).